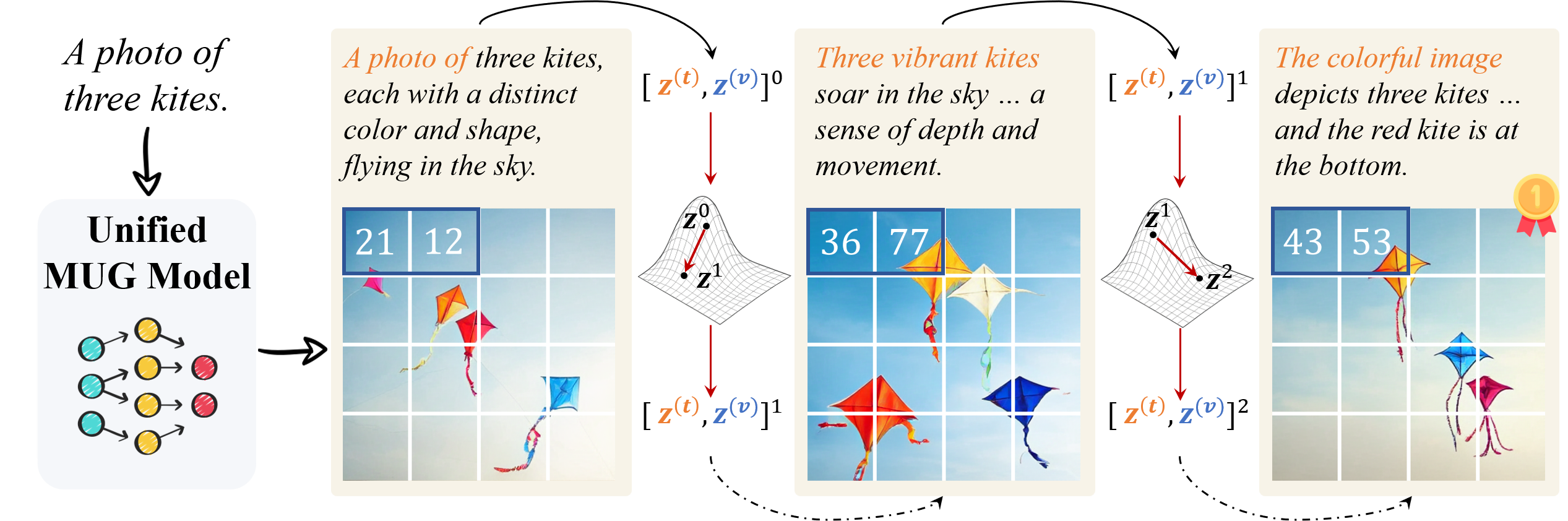
Reasoning-augmented machine learning systems have shown improved performance in various domains, including image generation. However, existing reasoning-based methods for image generation either restrict reasoning to a single modality (image or text) or rely on high-quality reasoning data for fine-tuning. To tackle these limitations, we propose MILR, a test-time method that jointly reasons over image and text in a unified latent vector space. Reasoning in MILR is performed by searching through vector representations of discrete image and text tokens. Practically, this is implemented via the policy gradient method, guided by an image quality critic. We instantiate MILR within the unified multimodal understanding and generation framework that natively supports language reasoning before image synthesis and thus facilitates cross-modal reasoning. The intermediate model outputs, which are to be optimized, serve as the unified latent space, enabling MILR to operate entirely at test time. We evaluate MILR on GenEval, T2I-CompBench, and WISE, achieving state-of-the-art results on all benchmarks. Notably, on knowledge-intensive WISE, MILR attains an overall score of 0.63, improving over the baseline by 80%. Our further analysis indicates that joint reasoning in the unified latent space is the key to its strong performance. Moreover, our qualitative studies reveal MILR's non-trivial ability in temporal and cultural reasoning, highlighting the efficacy of our reasoning method.
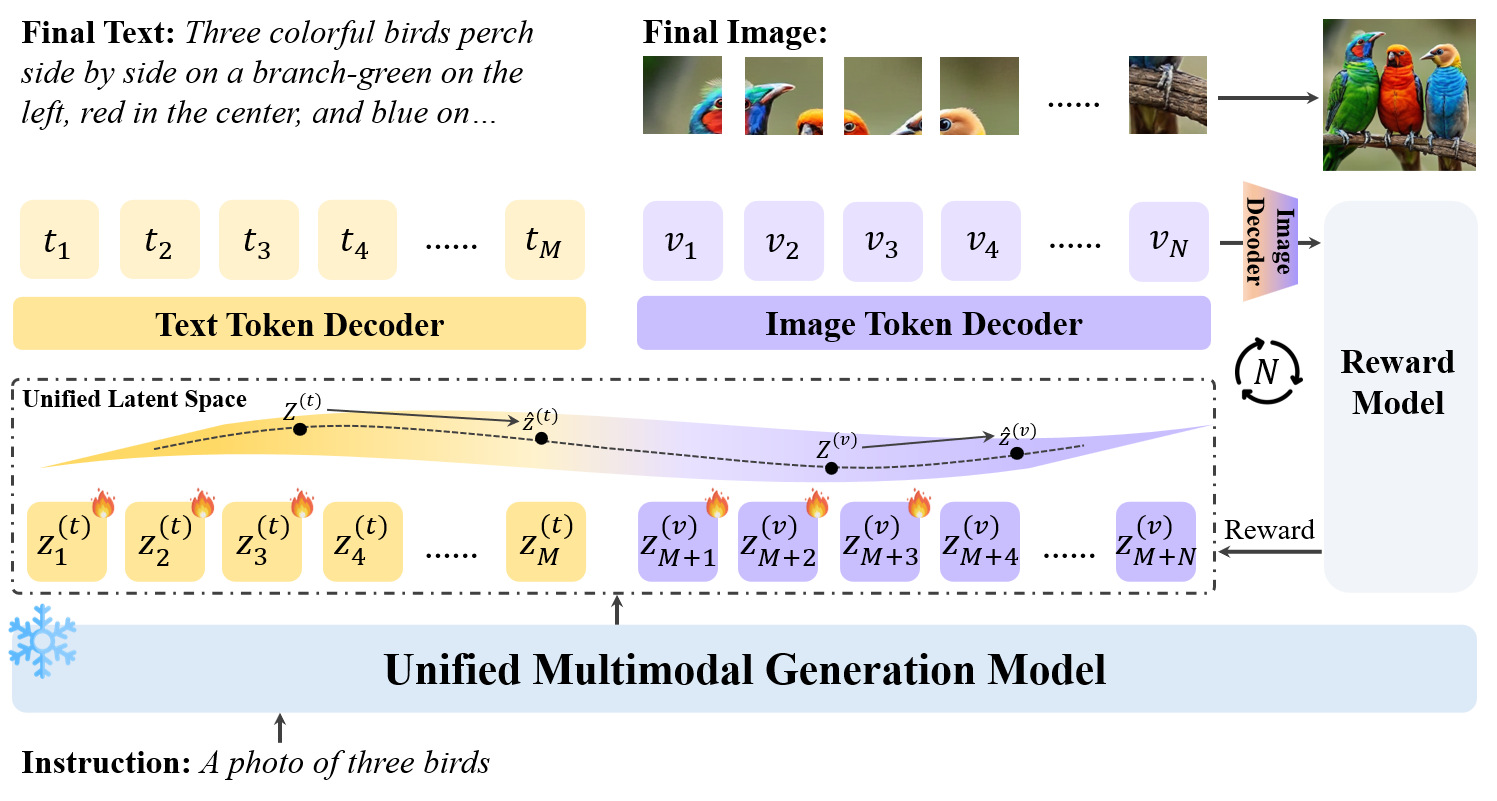
Formally, denoting the latent representations of image and text tokens by \( \mathbf{z}^{(v)} = z^{(v)}_{1:N} \) and \( \mathbf{z}^{(t)} = z^{(t)}_{1:M} \), respectively, where \( z^{(v)}, z^{(t)} \in \mathbb{R}^{d} \) are the outputs from the same Transformer layer and thus lie in a shared \( d \)-dimensional vector space. The goal of latent reasoning is to find an optimal latent representation that maximizes the expected reward under \( p(\cdot \mid \mathbf{z}, c) \) without modifying any model parameters; we can therefore write the reasoning target as:
where \( \mathbf{z} = [\mathbf{z}^{(t)};\mathbf{z}^{(v)}] \) indicates the multimodal latent representation of the token sequence \( [\mathbf{t}, \mathbf{v}] \). We refer to this optimization problem as multimodal latent reasoning. Given the optimal \( \mathbf{z}^{\star} \) from a specific model layer, to produce the final \( V_f \), we continue the forward pass until it is decoded into discrete tokens \( [\mathbf{t}, \mathbf{v}] \). Thus, the pixel image generation becomes:
where \( p(\mathbf{t}, \mathbf{v} \mid \mathbf{z}^*) \) represents the remaining forward pass of MUG starting with \( \mathbf{z}^* \).
In general, the objective above has no closed-form solution, so we use REINFORCE, a policy-gradient method. Prior work applies it to fully textual reasoning; here we extend it to unified multimodal latent reasoning for image generation. With REINFORCE, the cross-modal update is:
Here, \( \eta \) is the learning rate. For efficiency, we take \( \mathbf{z} \) from the last Transformer layer (inputs to the modality-specific decoding heads). We approximate \( \mathcal{J}(\mathbf{z}) \) with a single sampled pair \( (\mathbf{t}, \mathbf{v}) \). Gradients back-propagate only to the outputs \( \mathbf{z} \), leaving model parameters unchanged, making MILR a test-time reasoning method.
Naively, we would optimize all \( M+N \) latents in \( \mathbf{z}_{1:M+N} \), but searching using only the guidance of a reward model is potentially biased and does not leverage MUG’s generative capacity for exploration. Instead, we optimize only the first \( \lambda_{t} M \) latents for text with \( \lambda_{t}\in(0,1] \)); after decoding them into discrete tokens, we complete textual reasoning via standard autoregressive generation conditioned on them. For visual reasoning, we adopt a similar strategy and optimize the first \( \lambda_{v} N \) latents with \( \lambda_{v}\in(0,1] \)), consistent with observations that the first few tokens govern global image structure while the remaining tokens primarily influence high-frequency details. The full algorithm is shown below.


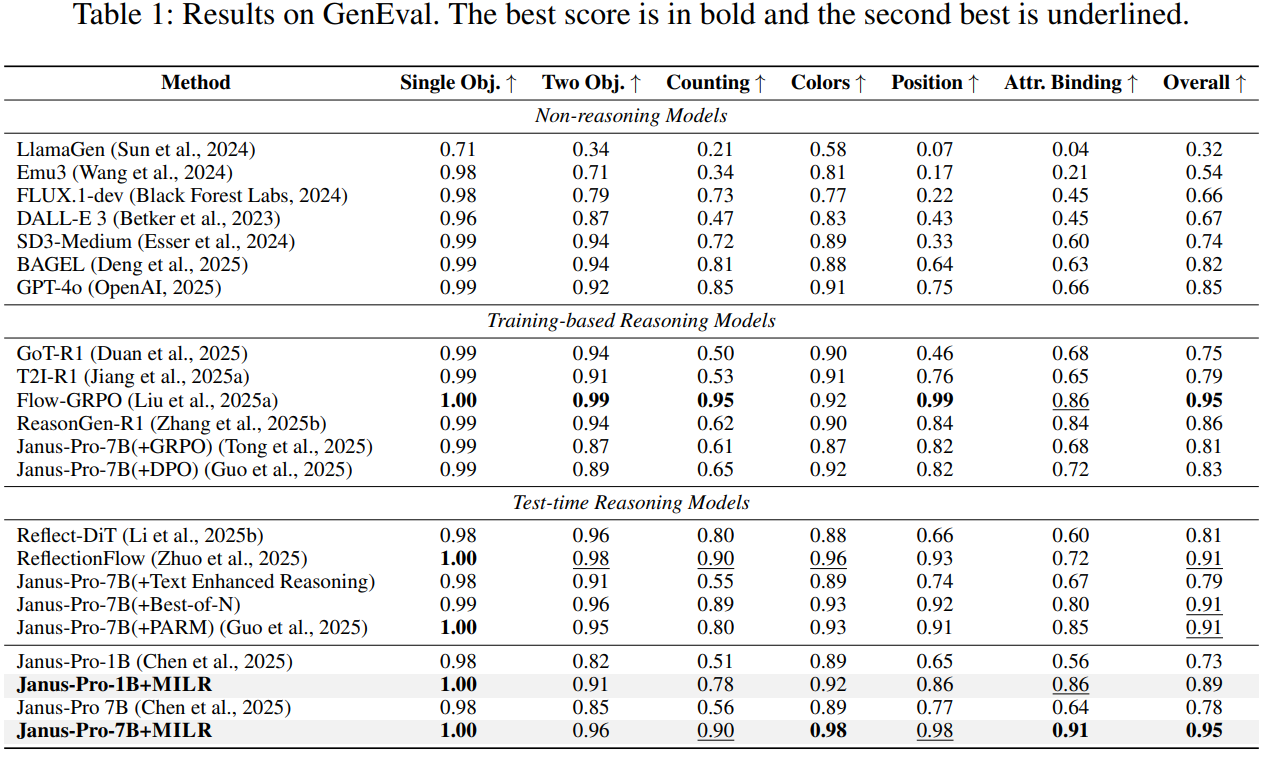
MILR achieves state-of-the-art results on GenEval, one of the most widely-used benchmarks for image generation (see Table 1). It improves over the base Janus-Pro-7B by 0.17, with the largest increases obtained from Counting (+0.34), Position (+0.21), and Attribute Binding (+0.27). Notably, MILR surpasses frontier non-reasoning models such as SD3-Medium, BAGEL, and GPT-4o (+12%). Compared with training-based reasoning models (e.g., GoT-R1 and T2I-R1), MILR performs better and requires no parameter tuning. For fairness, we also compare MILR with test-time reasoning models. Surprisingly, it outperforms ReflectionFlow and PARM (+4.5%) that rely on scaling up test-time computation, demonstrating the superiority of our test-time optimization method.
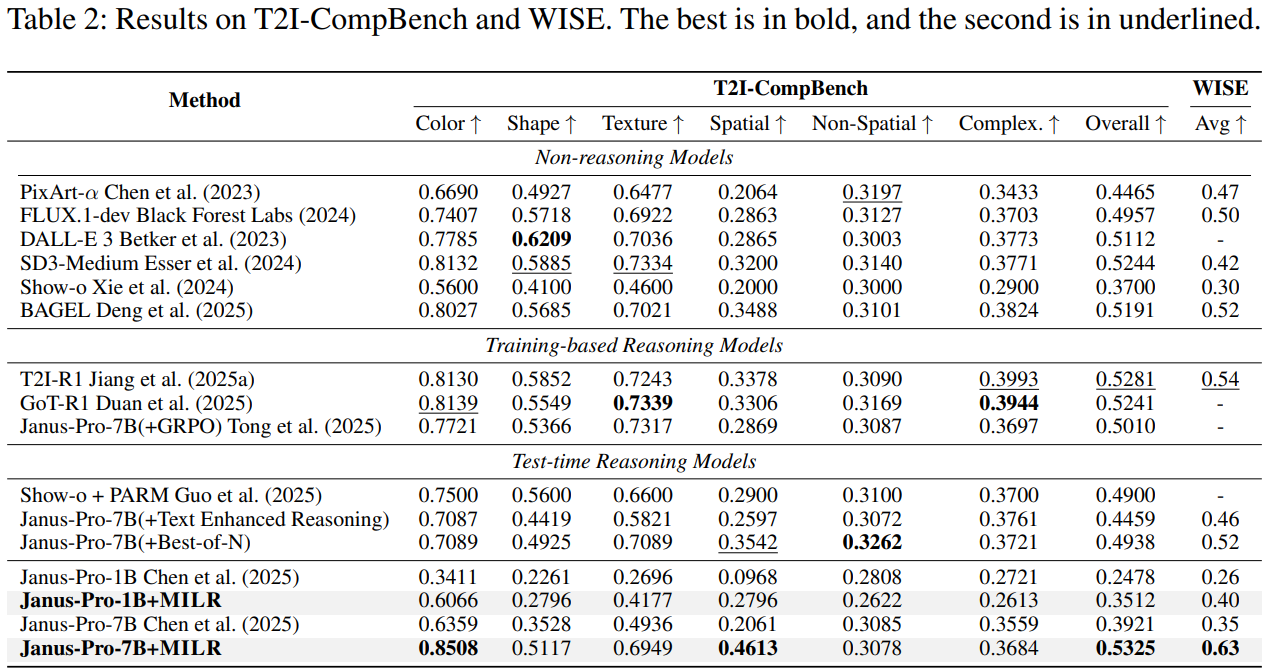
We further evaluate MILR on two additional benchmarks: T2I-CompBench and WISE (see Table 2). Again, it achieves the best performance on both, highlighting the robustness of our model. Specifically, on T2I-CompBench, MILR improves over the base Janus-Pro-7B by a large margin (+0.14) and slightly outperforms T2I-R1, a strong training-based reasoning model. On WISE, which emphasizes world knowledge understanding, MILR outperforms the base Janus-Pro-7B (+80%) and the second-best model T2I-R1 (+16.7%), implying the importance of reasoning in comprehending knowledge-intensive instructions. The case comparation is shown in Figure 3.

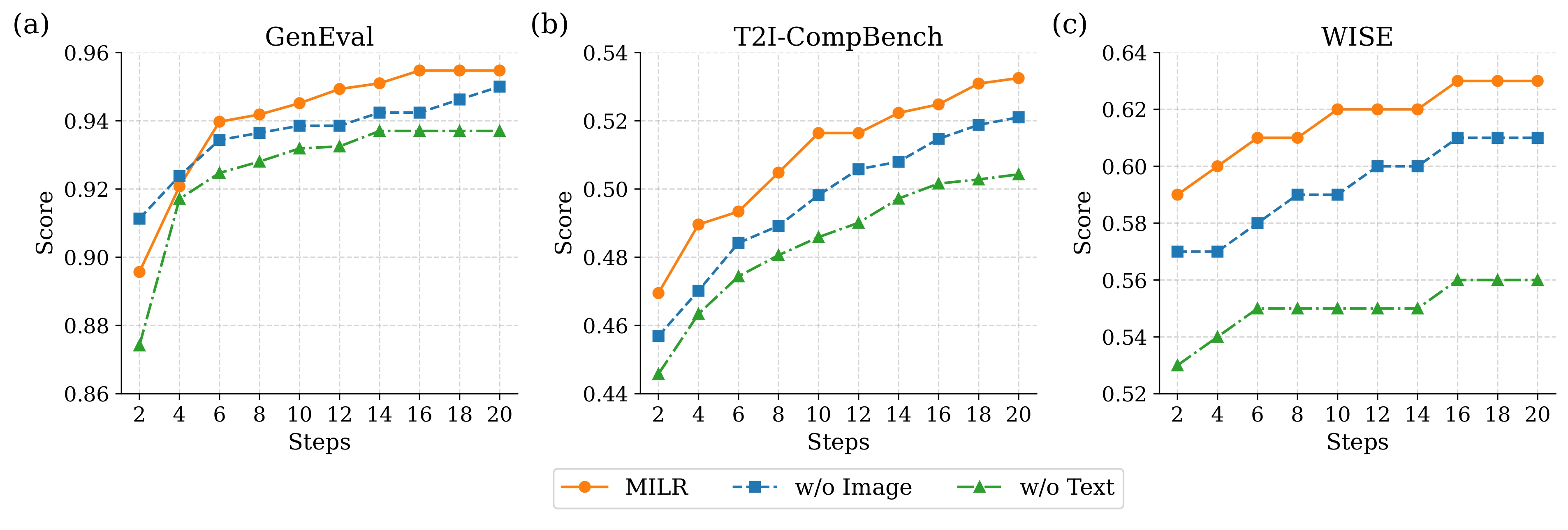
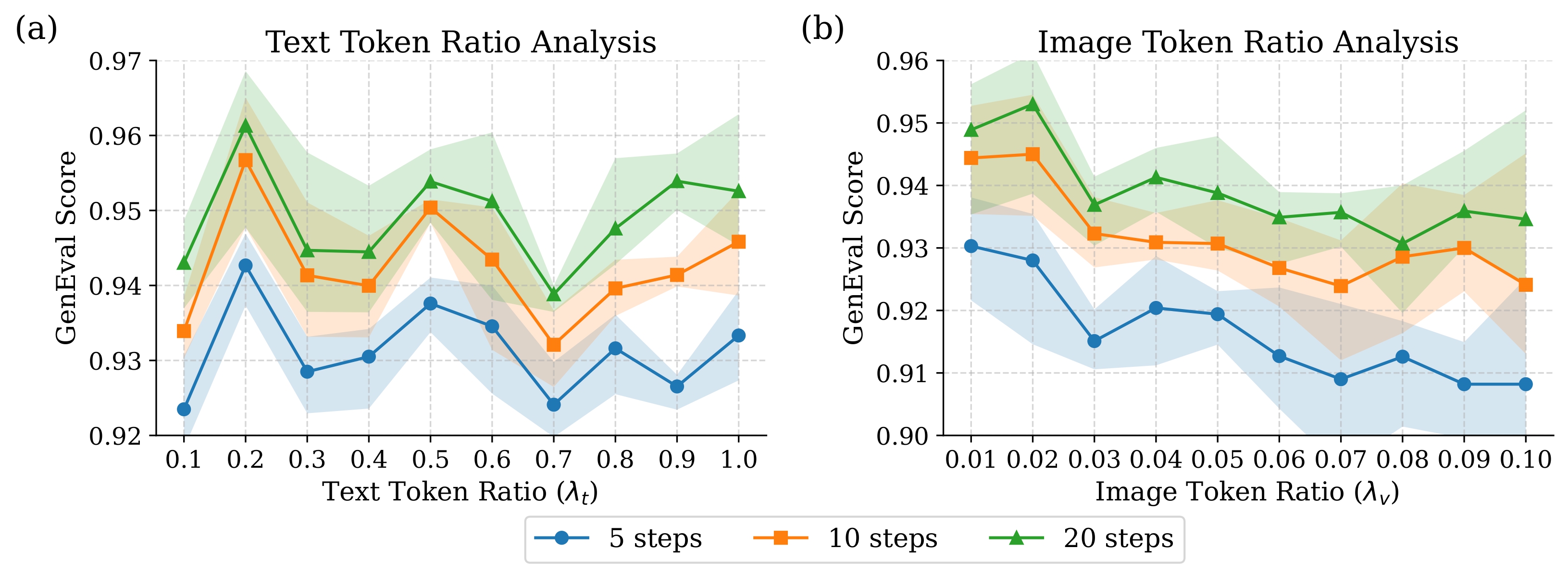
We analyze three important hyperparameters of MILR: (1) the maximum optimization step T (shown in Figure 4), (2) the portion of text tokens to be optimized λt in text-only optimization(shown in Figure 5), and (3) the proportion of image tokens to be optimized λv in image-only optimization(shown in Figure 5). And we have the following findings:
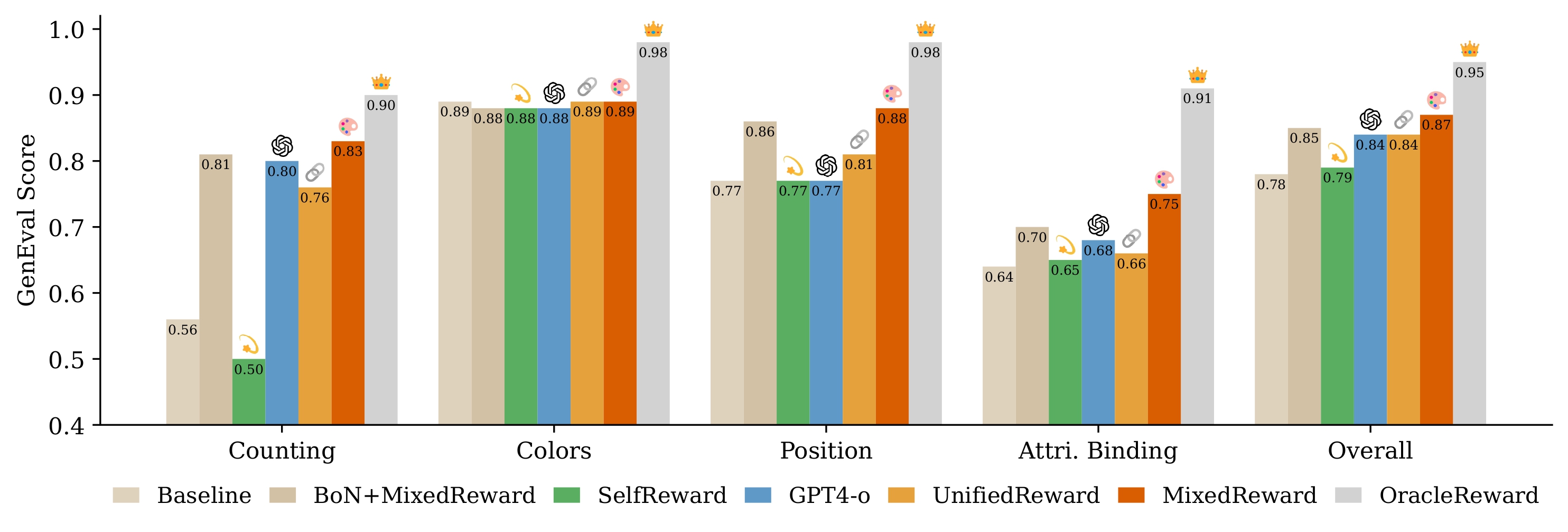
To show that MILR is effective without the reliance on ![]() OracleReward, we test it with a set of off-the-shelf
reward models on GenEval:
OracleReward, we test it with a set of off-the-shelf
reward models on GenEval:
Unsurprisingly, ![]() gives rise to the best performance across all dimensions (see Figure 6).
For nonoracle critics, all variants surpass the baseline in terms of the overall score. Notably, MILR remains
relatively robust to different reward models, except for
gives rise to the best performance across all dimensions (see Figure 6).
For nonoracle critics, all variants surpass the baseline in terms of the overall score. Notably, MILR remains
relatively robust to different reward models, except for ![]() , which performs poorly on Counting
(around 0.5). Among non-oracle critics,
, which performs poorly on Counting
(around 0.5). Among non-oracle critics, ![]() performs the best, suggesting that, in the absence of oracle rewards, we can derive a strong universal reward model by combining specialized critic models.
Moreover, MILR+
performs the best, suggesting that, in the absence of oracle rewards, we can derive a strong universal reward model by combining specialized critic models.
Moreover, MILR+![]() slightly outperforms the strong Best-of-N+
slightly outperforms the strong Best-of-N+![]() baseline (+2.4%) under comparable computation (i.e., N = T = 20), once again demonstrating the superiority of our method.
baseline (+2.4%) under comparable computation (i.e., N = T = 20), once again demonstrating the superiority of our method.
@article{mi2025milr,
title={MILR: Improving Multimodal Image Generation via Test-Time Latent Reasoning},
author={Mi, Yapeng and Li, Hengli and Zhao, Yanpeng and Li, Chenxi and Wu, Huimin and Ma, Xiaojian and Zhu, Song-Chun and Wu, Ying Nian and Li, Qing},
journal={arXiv preprint arXiv:2509.22761},
year={2025}
}